Swift Reversing

Hi, I'm Ryan Stortz and this is Swift Reversing. This is about the Apple programming language, not the inter-banking network. I'd probably have a solid gold laptop if I knew anything about Swift internals.

This talk is broken into 3 parts: an introduction to Swift, a discussion on my methodology, and the actual results from my research.

Swift is Apple's sexy new language for the future. Just like everything Apple does, it was more ceremony than substance for the first version release. iPad v1, iPhone v1, and Apple Watch customers will understand. More interestingly, Swift is meant to take over for Objective C and we can get behind that.
Swift was open-sourced back in December. It's technically available on Linux as well as on os x, but so was objc – so we'll see how that goes. A few months ago, MacRumors said Google is considering adopting Swift for android. With this and Ubuntu on Windows, we have some exciting times coming.
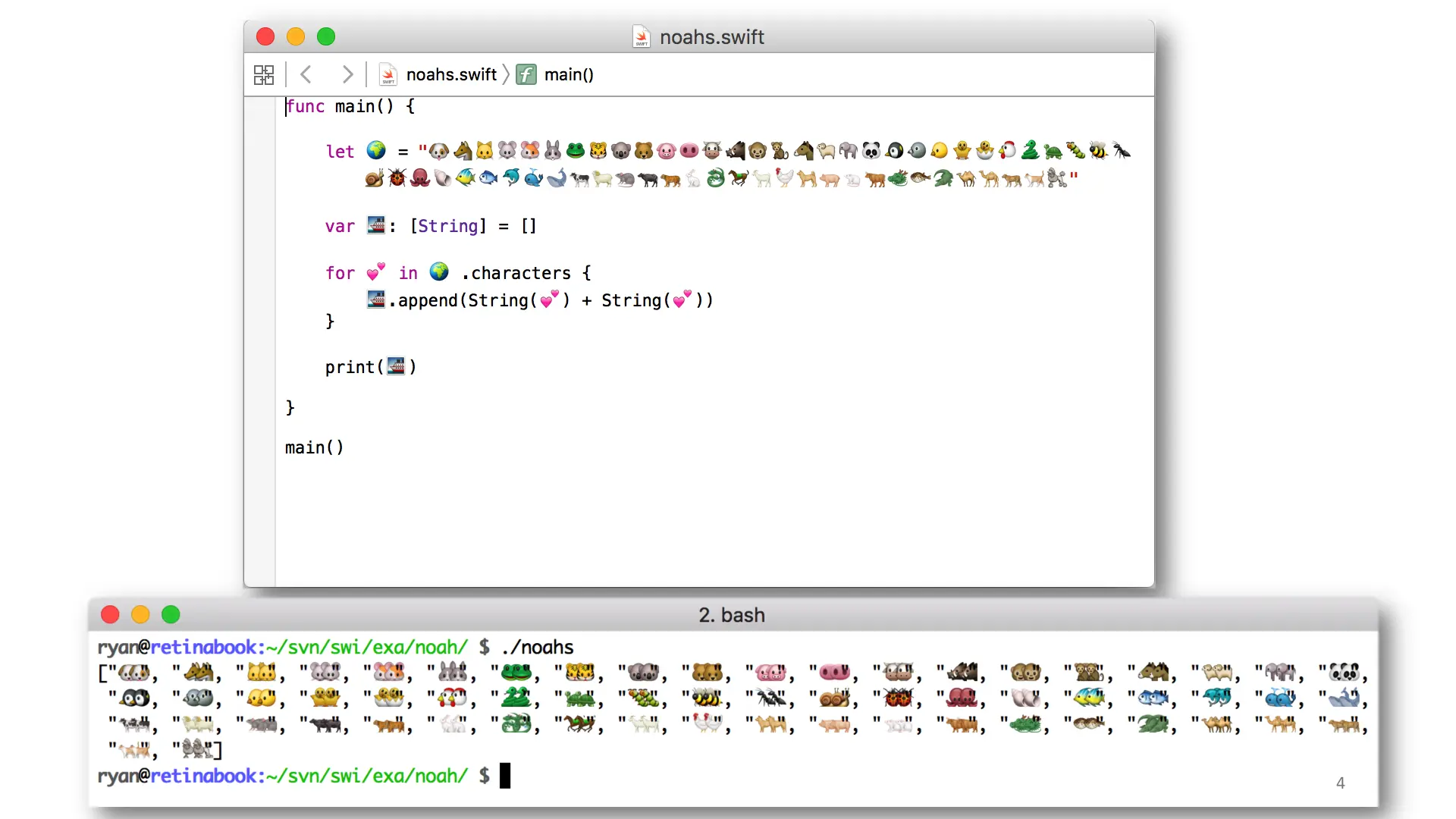
Swift is pretty expressive, you can commit atrocities like this one: Noak's Ark. As you can see, we have the world and all the animals in the world. Then we allocate the ark as an array of strings. Then we iterate over each animal and 💕+💕 and two by two, we fill the ark.
Swift is meant to be a systems programming language or close to it. It's not interpreted or JITed like Python and Java (respectively). Meaning all of these emojis will be compiled into machine code.

Swift is a "modern language". I'm not really sure, but I think that means it was designed after Mudge invented the buffer overflow.
It has all the features you'd expect: closures, first-class functions, generics, etc. As a reverse engineer, more closures and generics could be problematic. These structs-that-are-really-classes might make certain cases easier to reverse. Swift also makes heavy use of optionals, which will likely add a ton of noise to the disassembly.
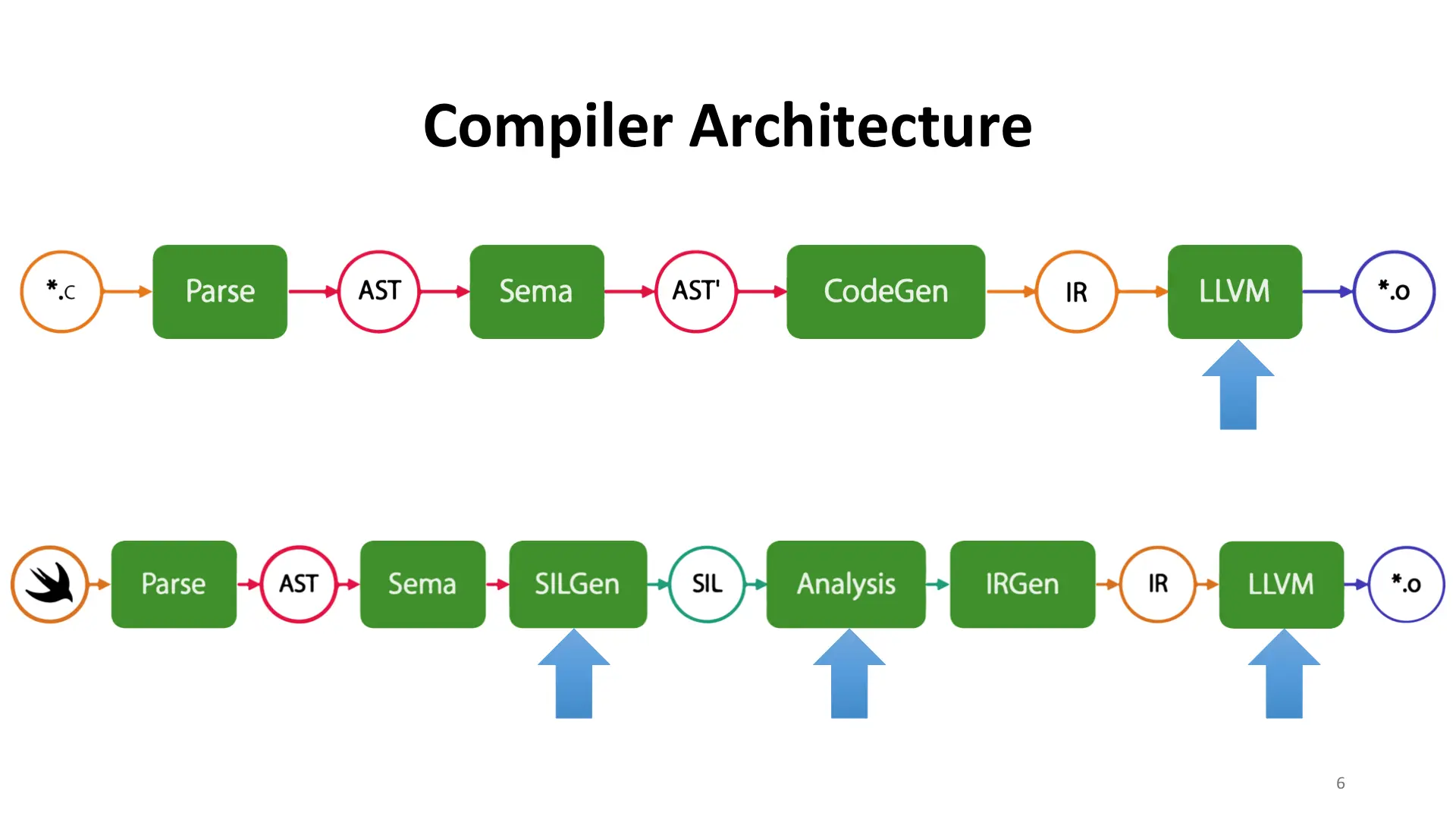
I'm going to take a small segue here and talk about the Swift compiler architecture. As I think it's important to understand to fully grasp Swift reverse engineering. These next few slides borrow heavily from Lattner's LLVM Dev Mtg presentation on SIL
Both clang and Swift (and rust and a million other compilers) are built on top of LLVM. Clang has a pretty minor set of C or C++-specific optimizations. Very little code is re-written due to language-level features or language usage. That being said, the resulting machine code is still fairly well optimized. Most of us can tell if the code was -O0 or -O3. This is neat as the vast majority of the optimization happens in LLVM-land, and languages like Swift and Rust benefit.
However, Swift was designed by the same people who designed clang and llvm and they learned from their mistakes. Swift introduces another intermediate language and does analysis and optimization. So where most of Clang's optimizations take place in a single location, Swift can optimize in several. In fact, Swift has a set of guaranteed optimizations that can't be disabled.
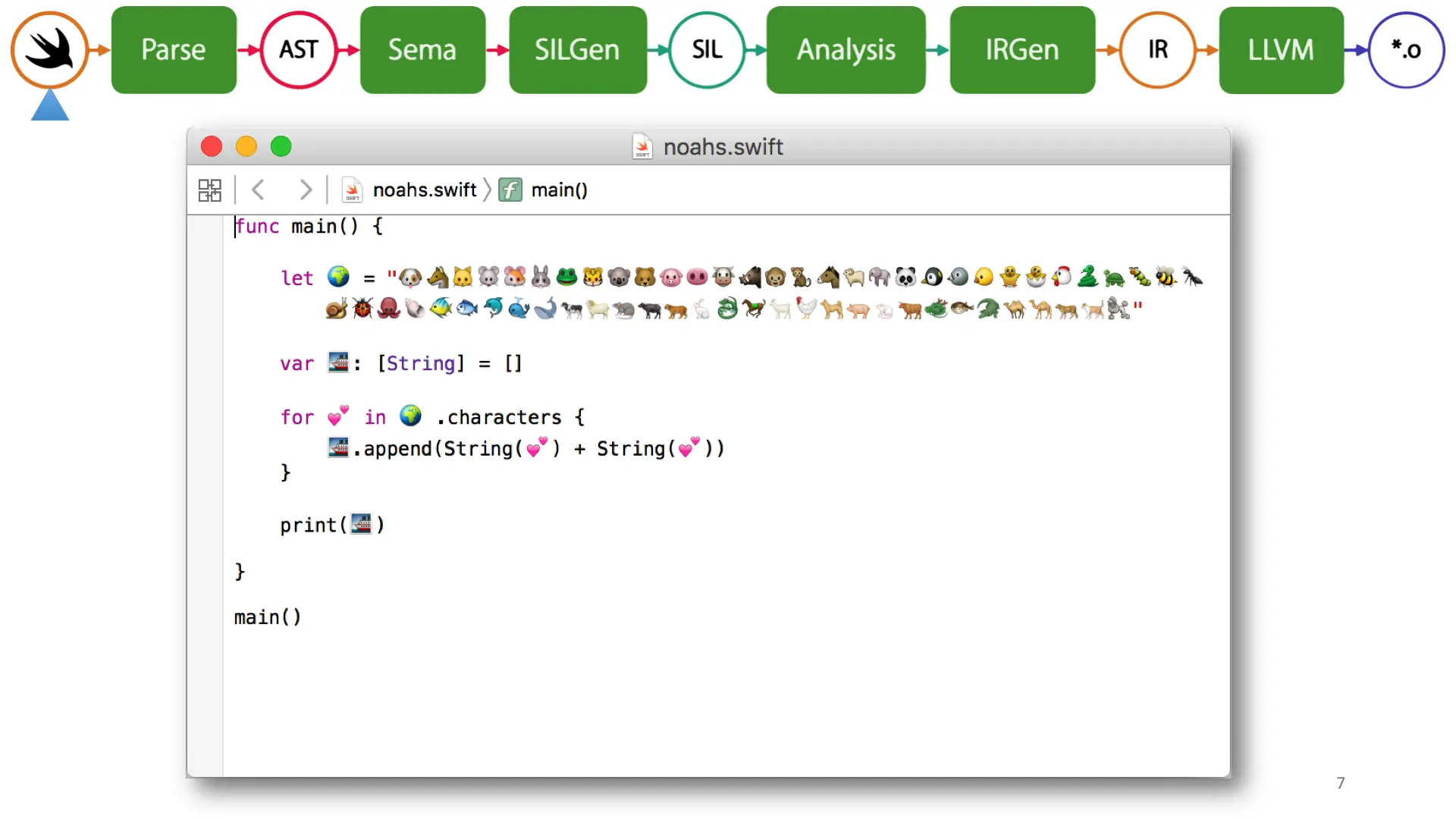
For a visual representation, let's take a little journey. We start at the parser and lexer and Swift and the Noah's ark example.
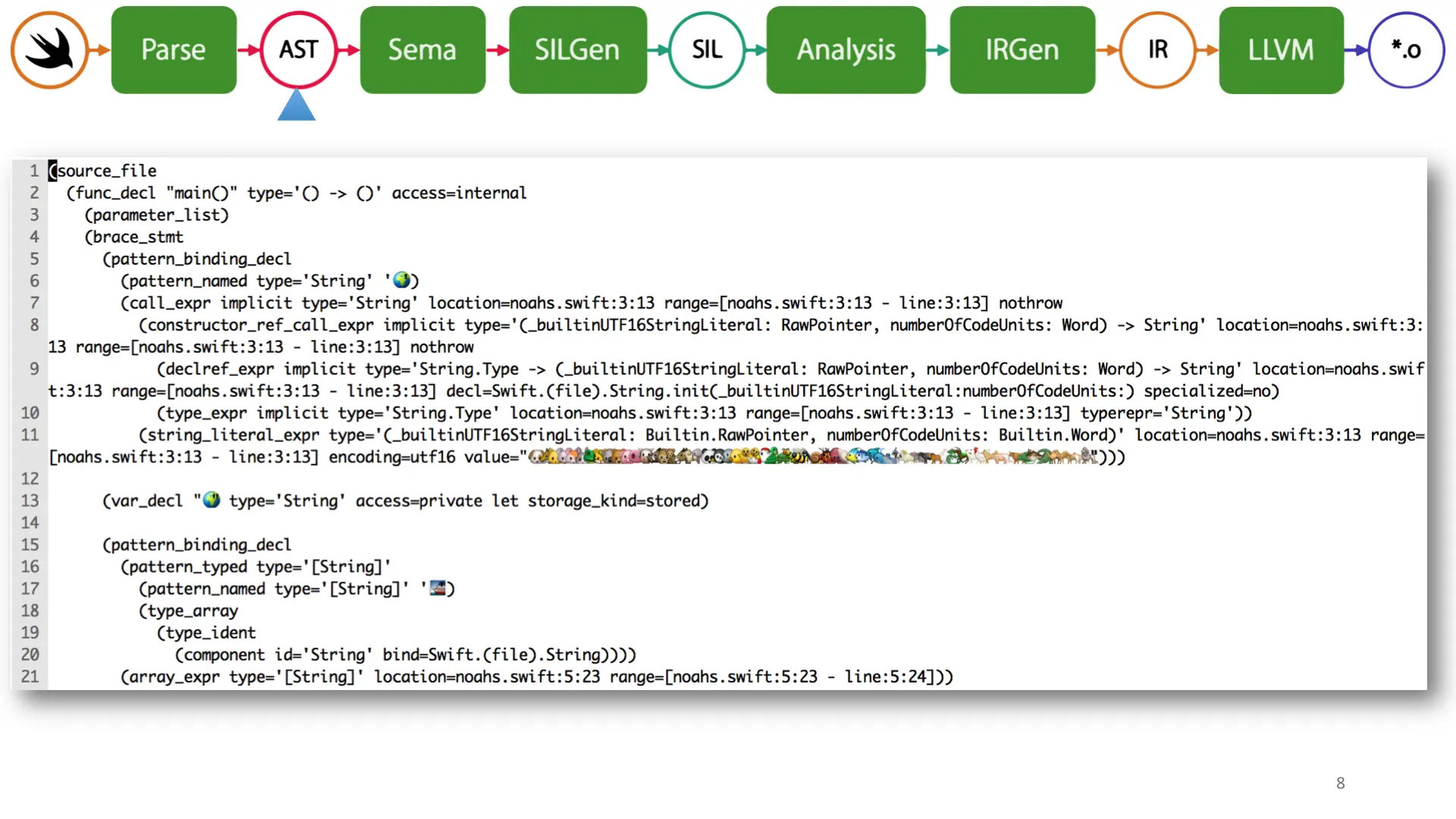
Next is the Swift code represented as an Abstract Syntax Tree.
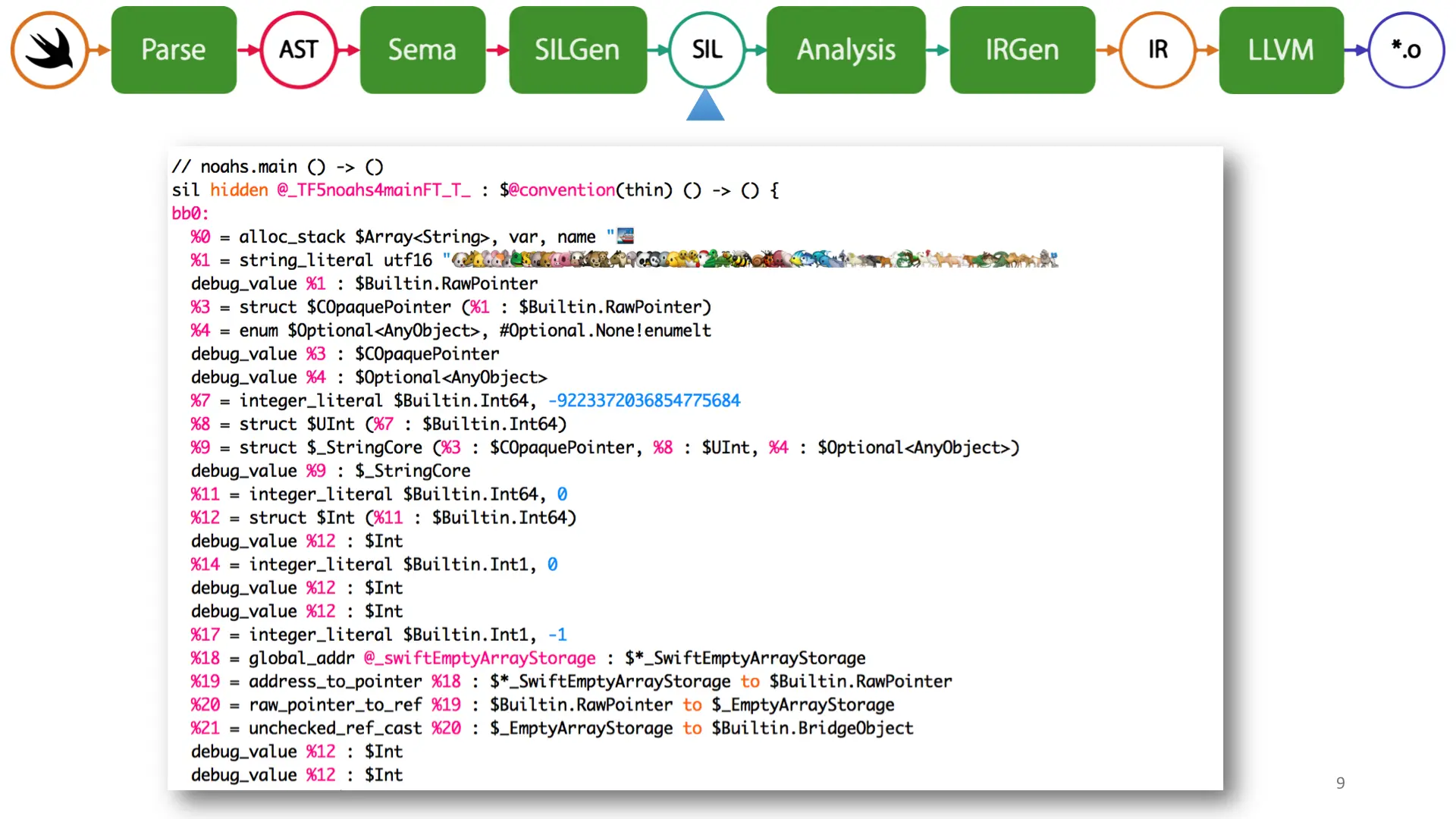
SILGen generates SIL, which is Swift's IL. Swift does its language-specific analysis on SIL, a new intermediate layer that's bolted on top of LLVM, but with a full awareness of Swift's type system. If you're familiar with LLVM or really any other SSA IR, you'll notice that this one is at a higher abstraction layer. This allows Swift to heavily optimize in a safe manner, and I'll get to an example in a moment.
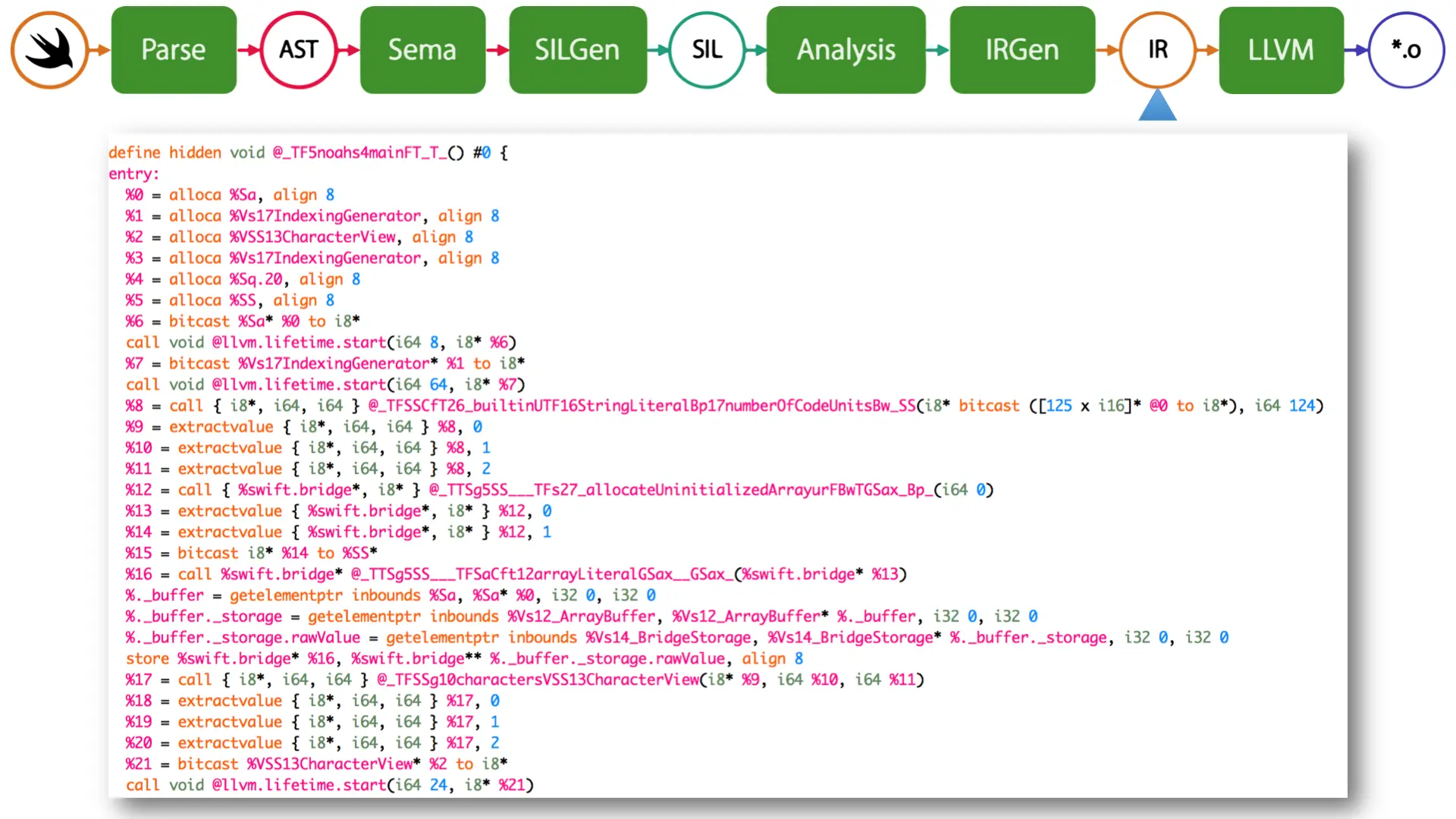
Next up is LLVM IR.
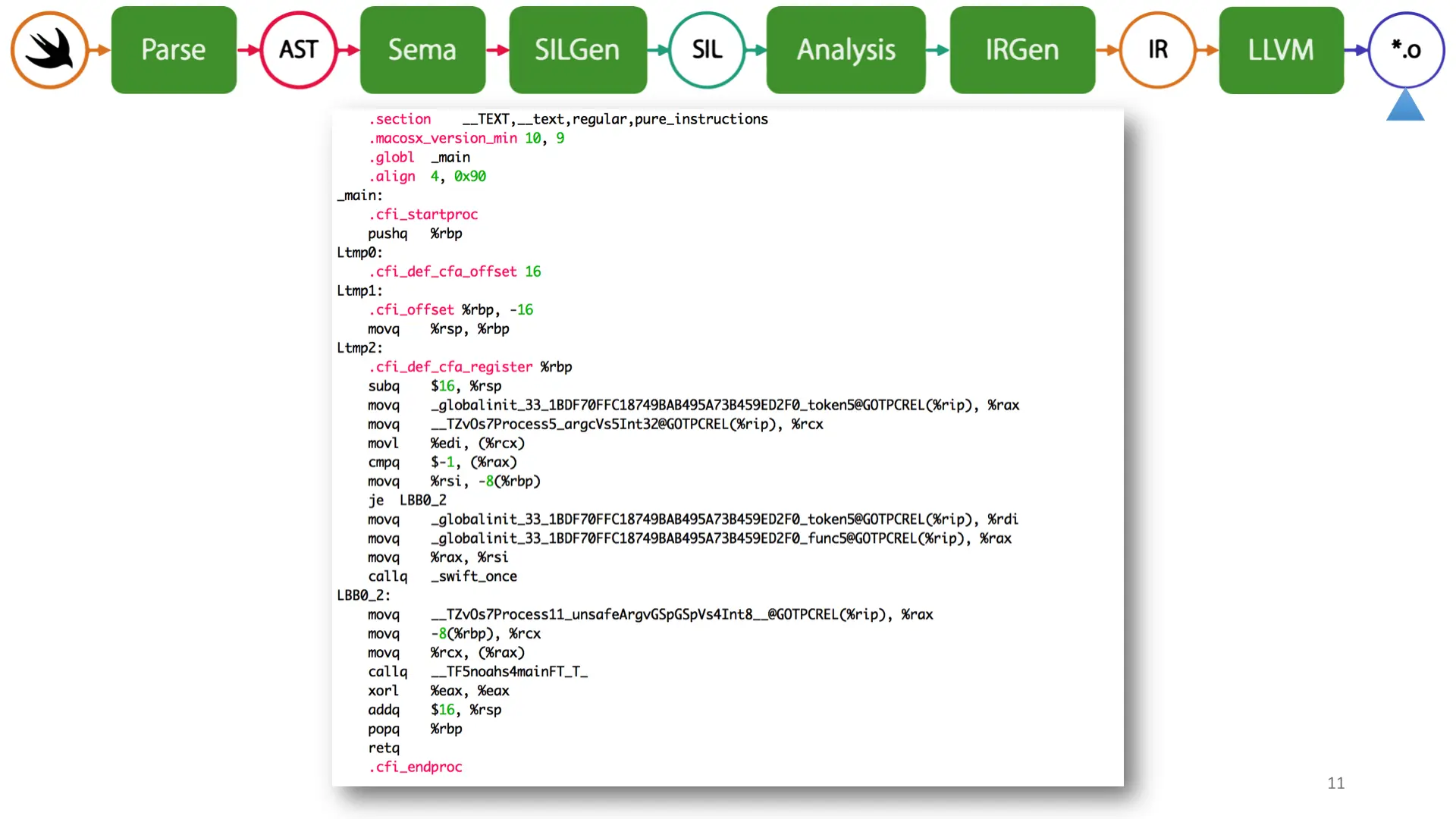
And finally, the llvm IR is compiled to a specific target. x86_64 in this case. My apologies for the AT&T syntax.

One last thing about SIL. Since Swift has many many ways to create closures, SIL has the alloc_box optimization which causes me a lot of heartache as a reverse engineer. By default, all variables and closures are allocated on the heap and then SIL's guaranteed optimizations do an escape analysis pass to determine if the variable or closure escapes its local scope. If it doesn't, it brings it onto the stack. This means there are 2-3 different representations for each variable and closure type.
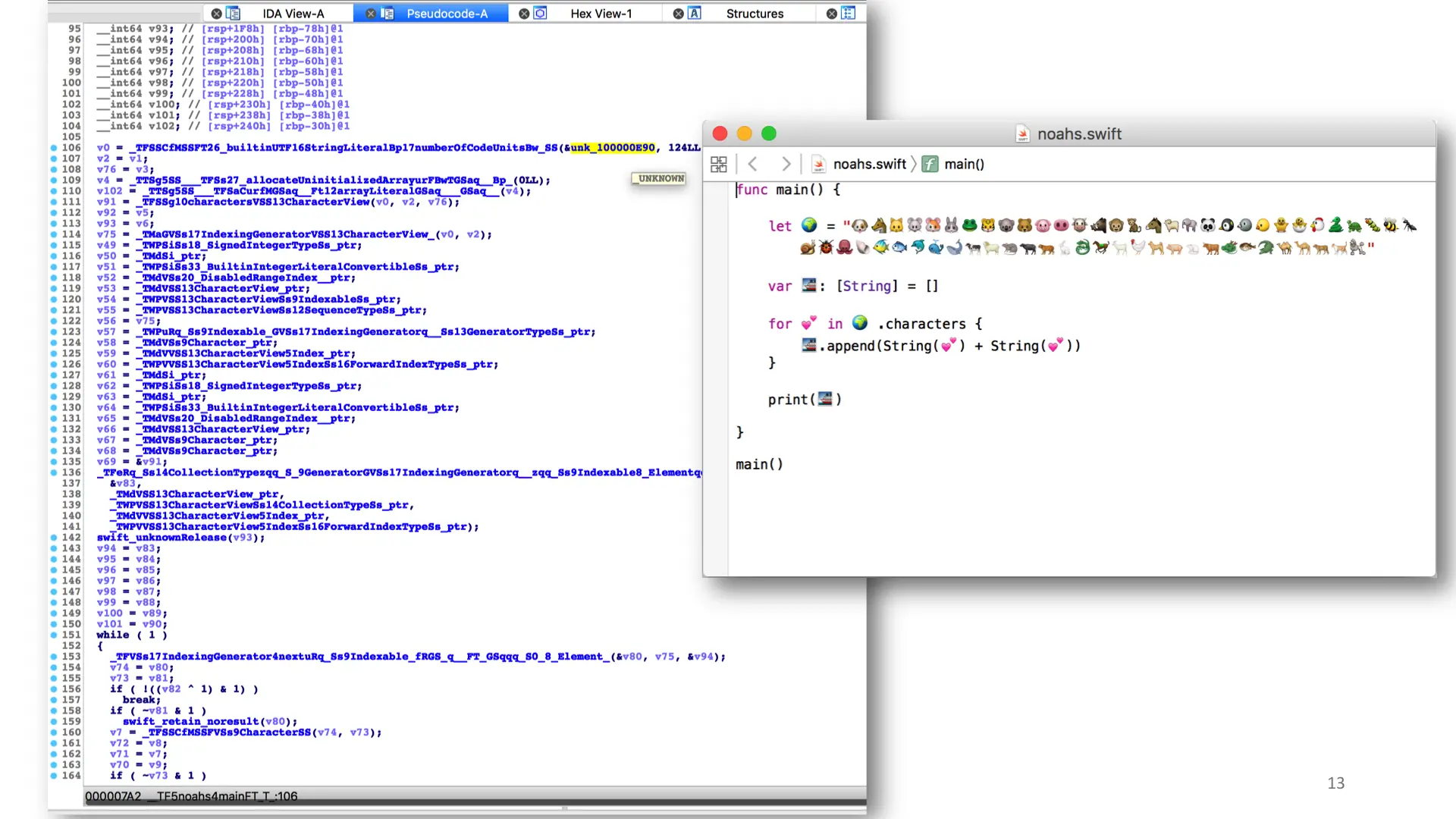
So enough about the compiler, let's figure out how to turn the code on the left into the code on the right.

On to methodology. I promised "a systematic approach" in my talk abstract, but it's more a list of things I was confused about going in.

I could probably spend months or years poking at the compiler and its output, trying to get a full grasp on the language, but nobody has time for that. So it's important to bookend the research. The research needs to be driven by the work. What's the motivation for tackling a new language?
I often start reversing projects with one of these first two in mind but frequently find myself just building character instead. This talk focuses on application pentesting with a little bit of character building.

My initial questions focused on three areas: the toolchain, the language core, and the ABI. What tools are available to me now? Is the language message-based like Objective-C? What's the Swift calling convention?
In general, you'd also ask some basic questions about the standard library but Swift's overlapped with Objective-C so much that I wasn't worried

For each question I had, I created one or more small projects that focused on using the one individual feature behind each question. I then compiled the project and threw it into everyone's favorite disassembler.
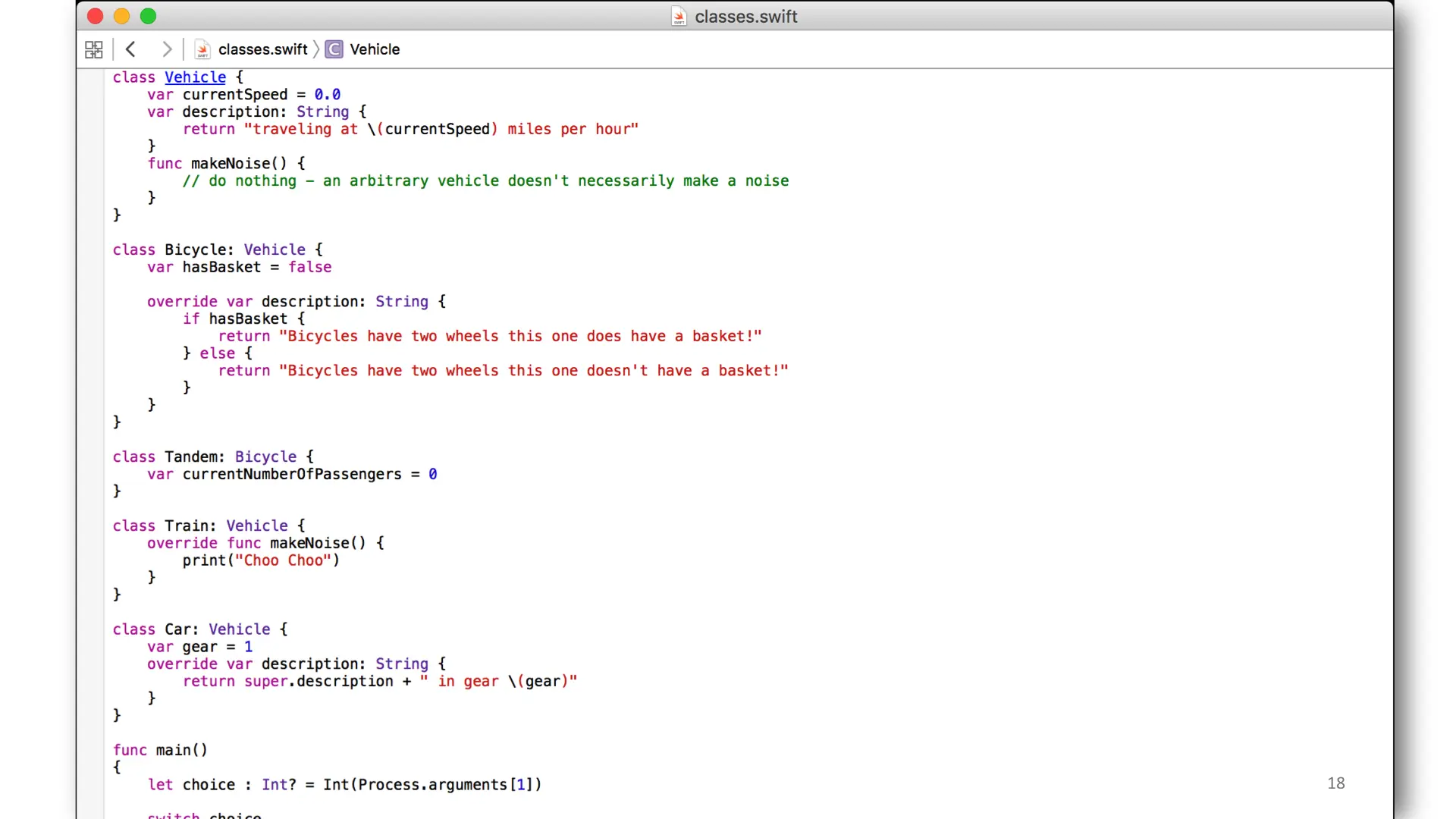
This one is a for class inheritance and it also uses optional unpacking/matching. We have our base class "Vehicle". Bicycle derives from it and Tandom derived from Bicycle.
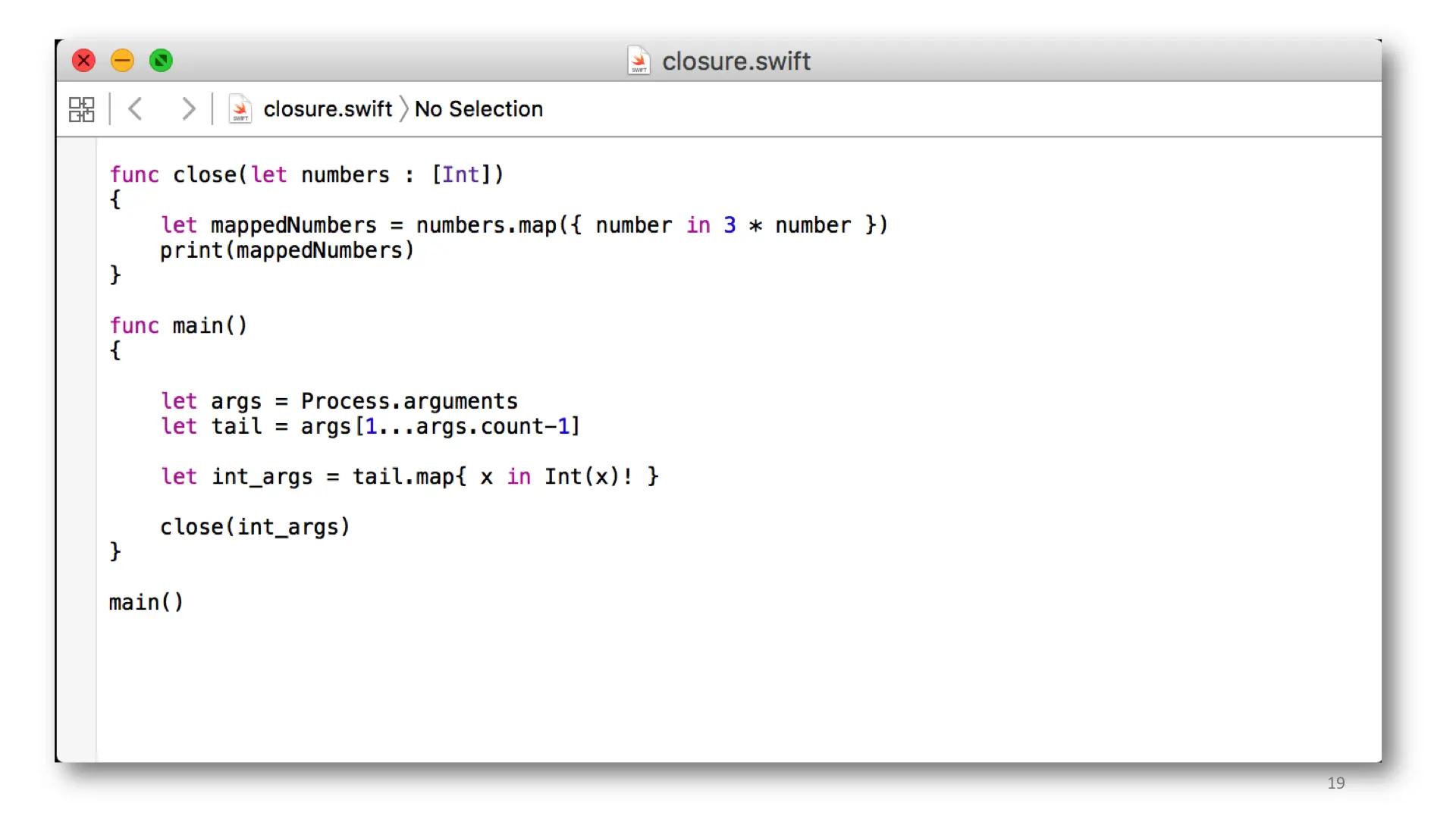
This one has an example closure. It actually has two, and several bugs.

Starting with the easiest section: The currently available tools and the Swift toolchain.
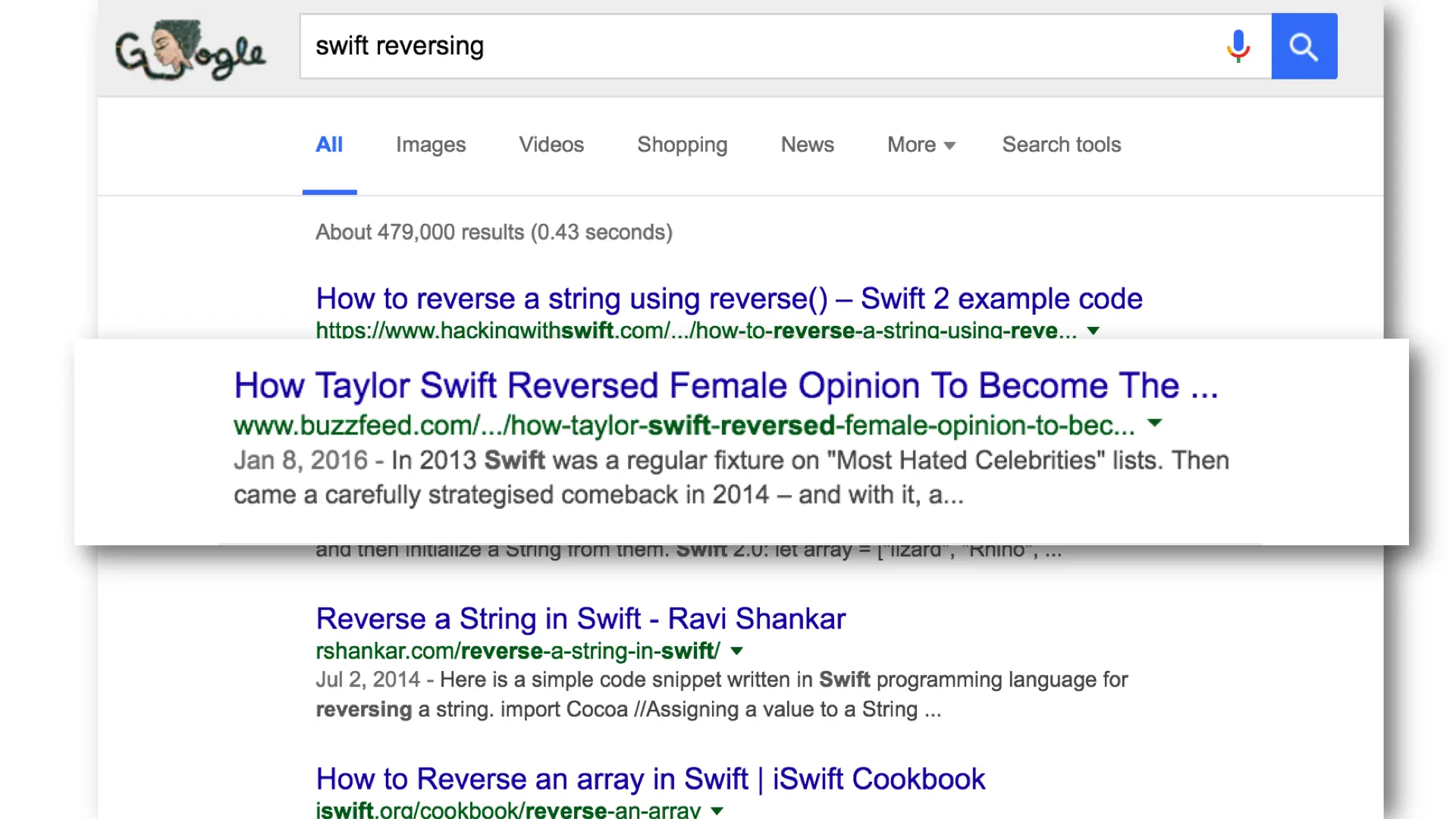
I started by Googling for Swift reversing. The first 9 results were about reversing a string or an array in Swift. The 10th result was how Taylor Swift reversed female opinions of her. So I knew my options were limited.

There isn't much here, but the Swift compiler provides some nice diagnostics and you can dump the SIL and LLVM IR for a better understanding. But this doesn't directly help you reverse engineer binary Swift executables.
We also have the Swift REPL and Swift-demangle.
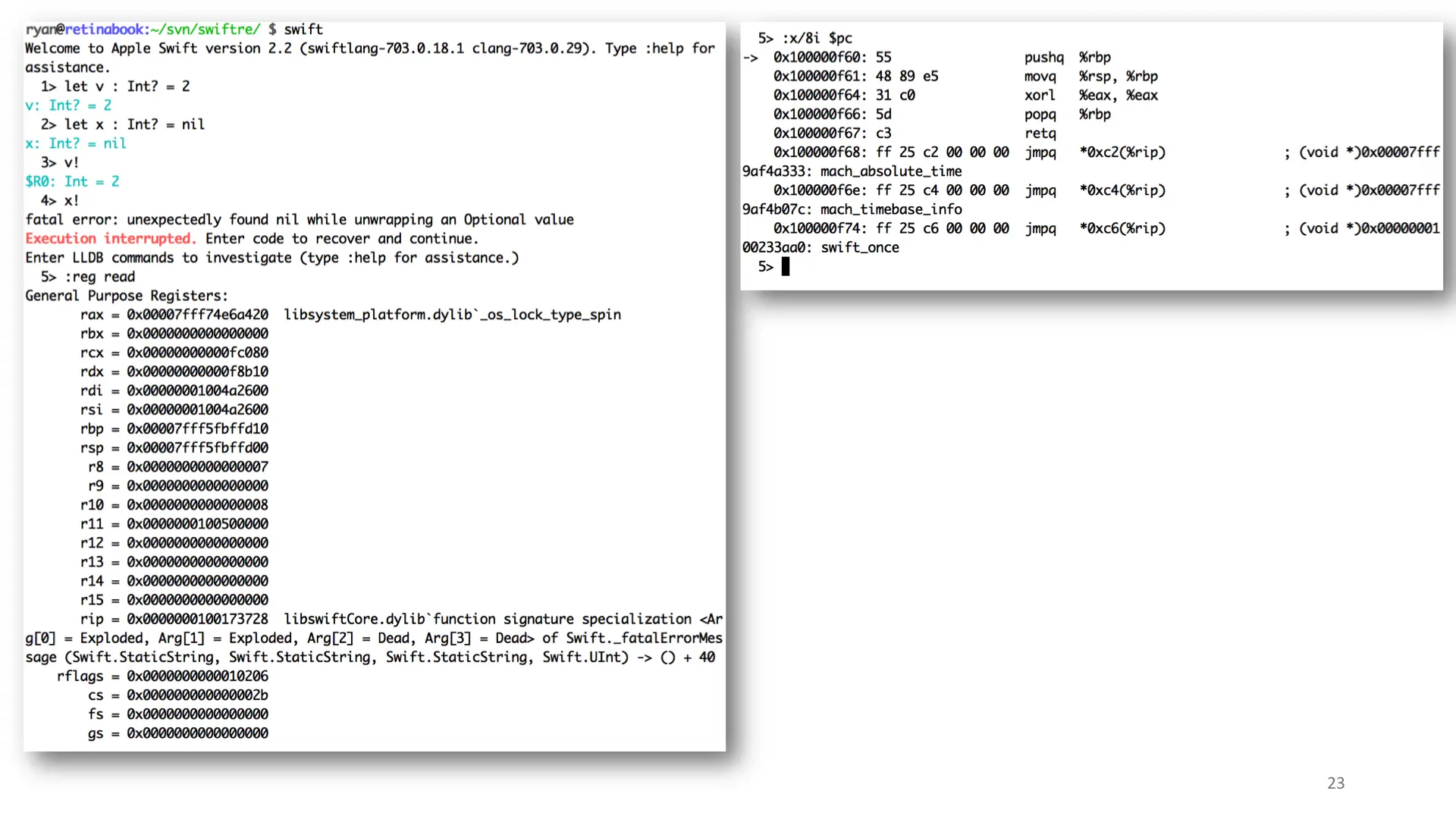
The Swift REPL is kind of fun, you can directly invoke lldb commands by prepending them with a colon. Useful for development but not so much for RE.
In my example, I force unpack an optional integer with a nil value. The REPL captures the crash and we can introspect it with lldb.

The most useful tool in the official toolchain is definitely Swift-demangle. It's not really much different than c++filt, except the demangled names are more expressive. Notice in this second example, it has this Arg[1] = Dead line. This encodes the ownership of the argument into the mangled name.

It also has an expanded view that prints the entire parse tree of the mangled name. This could be very useful for tools.

So for existing tools, we only have Swift-demangle. Class-dump, the Objective-C tool, actually parses a surprising amount of Swift classes, but it gets confused. It shouldn't be too hard to update it to support Swift.

Now on to the Language core.

There are a billion things I could put here. I decided to focus on the Native types, Control Flow, and Optionals. I've listed the native types, most of these decay into Swift.Builtin types and then decay into LLVM native types. On the right here you can see strings decay into ASCII c strings. I was somewhat surprised that it was an ASCII string and not a wide-character Unicode string. It's probably actually UTF-8.
For each language feature listed, I wrote one or two tiny test case projects that used only that feature. Then compiled that with and without optimization to better understand it.

Control flow is designed as any sane person would. Most calls are devirtualized and directly call the function with very little overhead. The only time you see ObjC messages is when you're doing a bridged call into ObjC code.
If this were Haskell or Haskell-like, you'd see the creation of thunks and thunk chains. So it isn't lazy. This is fortunate for us, as reversing Haskell is a ring of hell that Dante neglected to describe.

Optionals were of particular interest to me. They're going to be used a lot, as their use avoids a lot of really awful design paradigms (for the lack of a better word). Optionals are a safe way to encode an error condition and a value in the same "package" and enforce its proper checking.

Optionals are actually pretty thin. I don't know why, but I expected them to be big and bloated. The optional flag is stored as a 1 byte boolean. Up top we have the value .Some(2) and the value .None The Hex-Rays insert shows optional unwrapping. In this case, v51 is the optional flag. v52 is the pointer value that's getting retained.
Optional unpacking ends up being represented as a bitwise and of 1. It also happens to be the only time this is done. So optionals fall out easily.
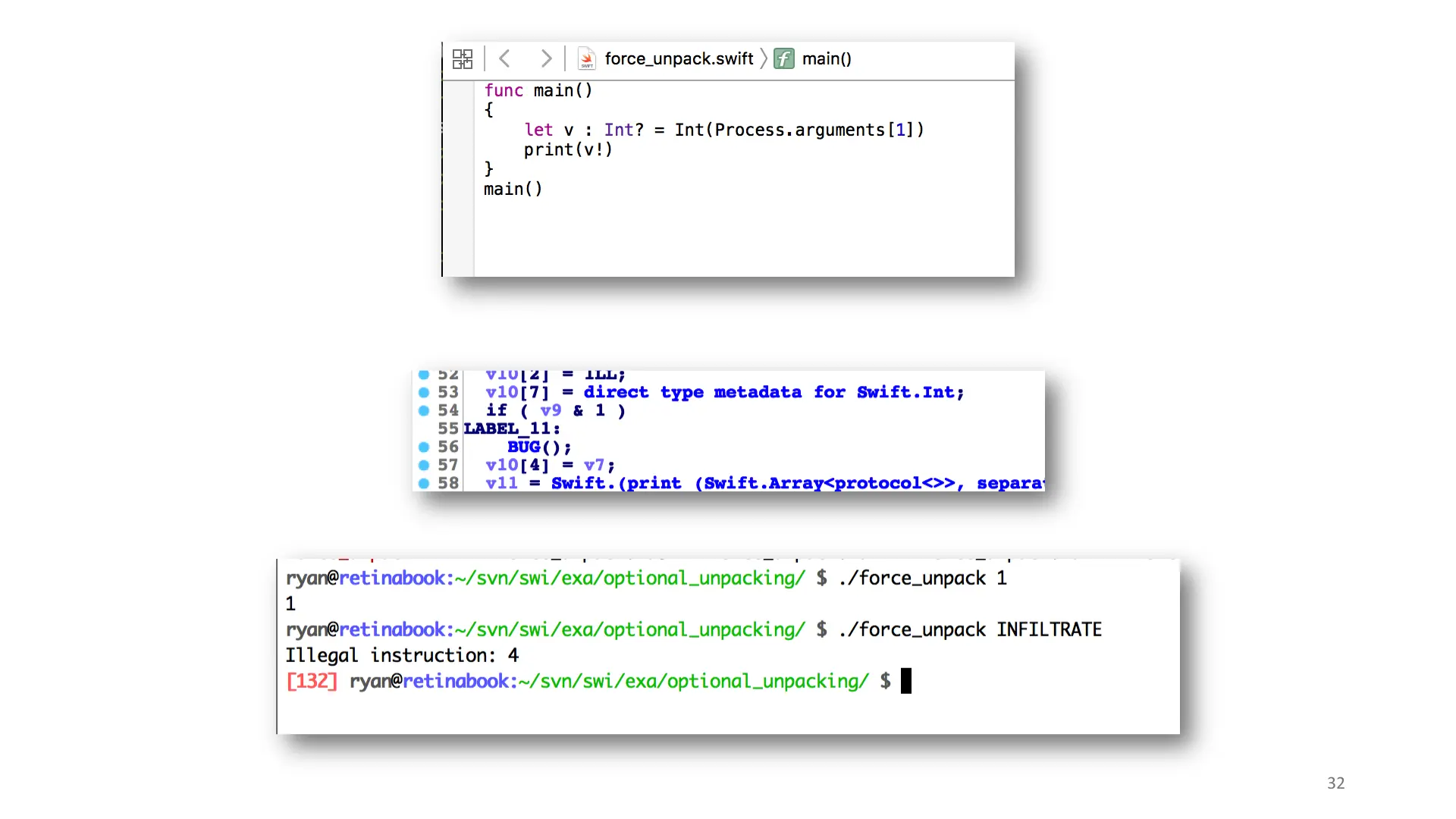
The compiler actually verifies that you properly unpack optionals. If you try to force unpack them, you hit an illegal instruction (represented as a ud2 on x86 and BUG() in HexRays).

As you'd expect from a higher-level language, you don't handle raw memory operations yourself. It turns out the way Swift handles this isn't much different than C++. There are minor differences related to accessing the type and passing that to Swift_allocateObject. In most (or maybe all) cases, you'll use the allocating_init form of the call which will handle everything.
In this example, we're allocating the Train class. Its size is 24 bytes, its alignment mask is 7 (aka 8 byte boundaries). It then passes the allocated memory to the train constructor. Interesting though, is v1: Swift's allocator cares about the type.

When looking into allocations, I discovered this fun comment in the declaration of Swift_allocObject. I thought it was interesting that it's "sometime after". I thought maybe there would be a potential race condition in the future.
In the end, it's really backed by the default "slow malloc", but it definitely piqued my interest originally and I'm waiting for them to "optimize" it and remove their todos.
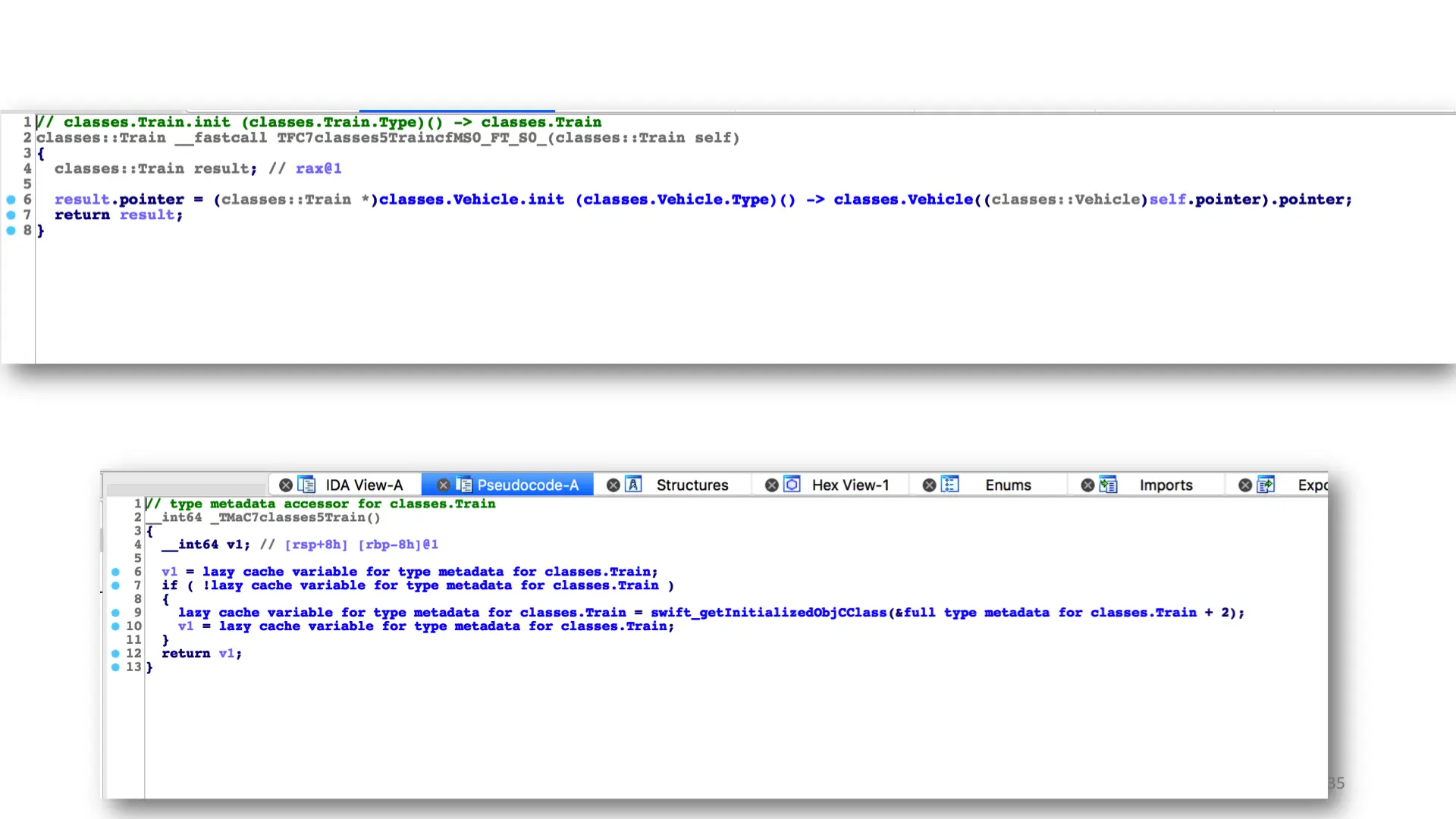
The train's "non-allocating" init, calls its parent classes' non-allocating init as well. It assigns its parent pointer. In C++, this function would be responsible for assigning the class's vtable. In our case, that's handled by Swift_allocObject.

Revisiting our questions, compiled Swift ends up looking a lot like C++. It's not lazy. It has all the expected native types.
The final area I researched was the Swift ABI.

Here I wanted to know how virtual function calls were made, ownership rules, and the calling convention

Bridging is quite difficult to do on the command line, but I did eventually get an example (and maybe I cheated with Xcode). Here I create an ObjC class that implements one method and I call it from Swift. Notice the compiler injected an objc_msgSend here, but actually allocated it with a Swift function. A funny mixing and matching.
Swift also has to decide if the returned object is managed by the Swift runtime or the ObjC runtime. It does that by checking to see if the object pointer has been tagged.
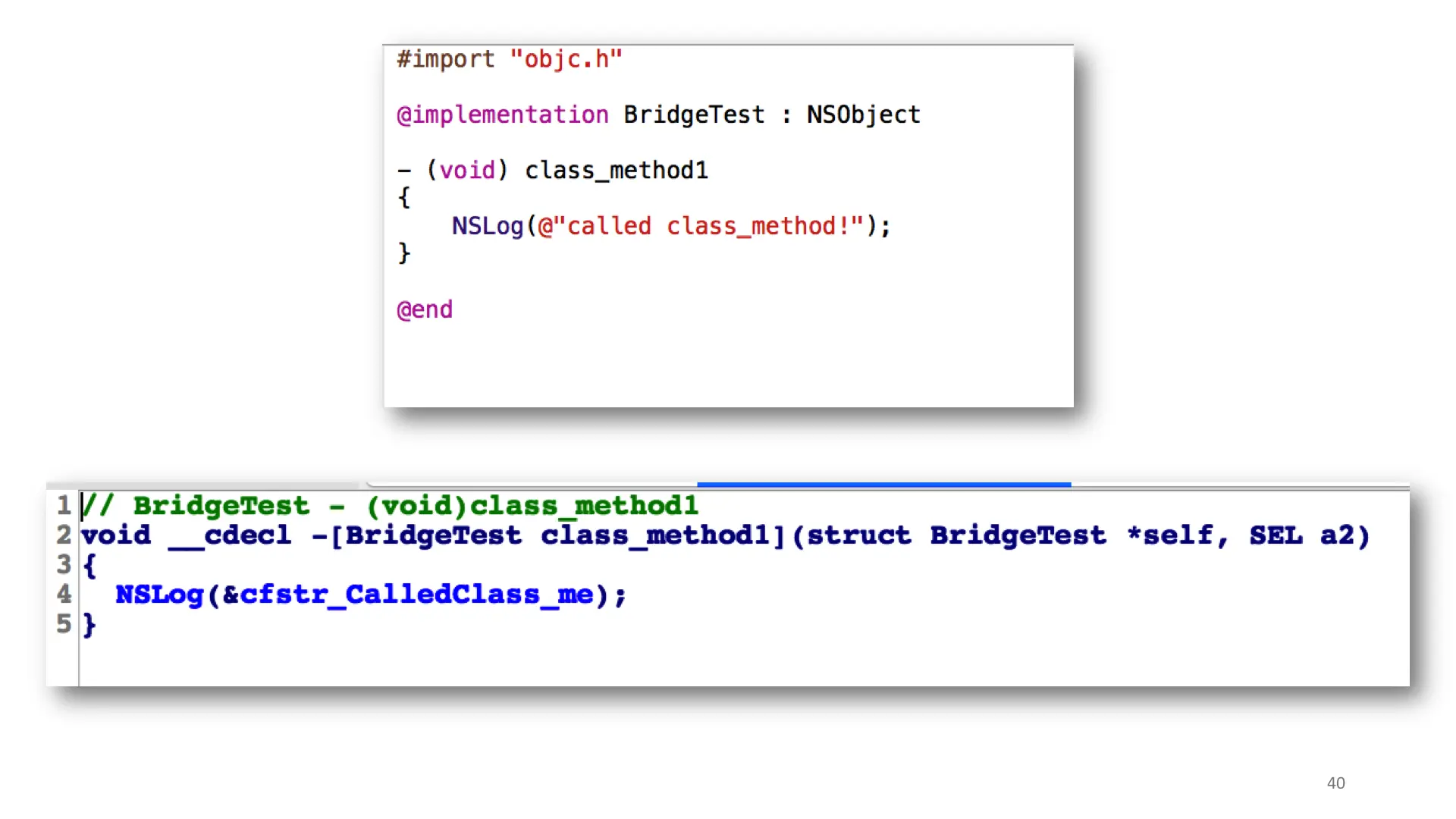
For reference, here's the Objective C class implementation. It's trivial.
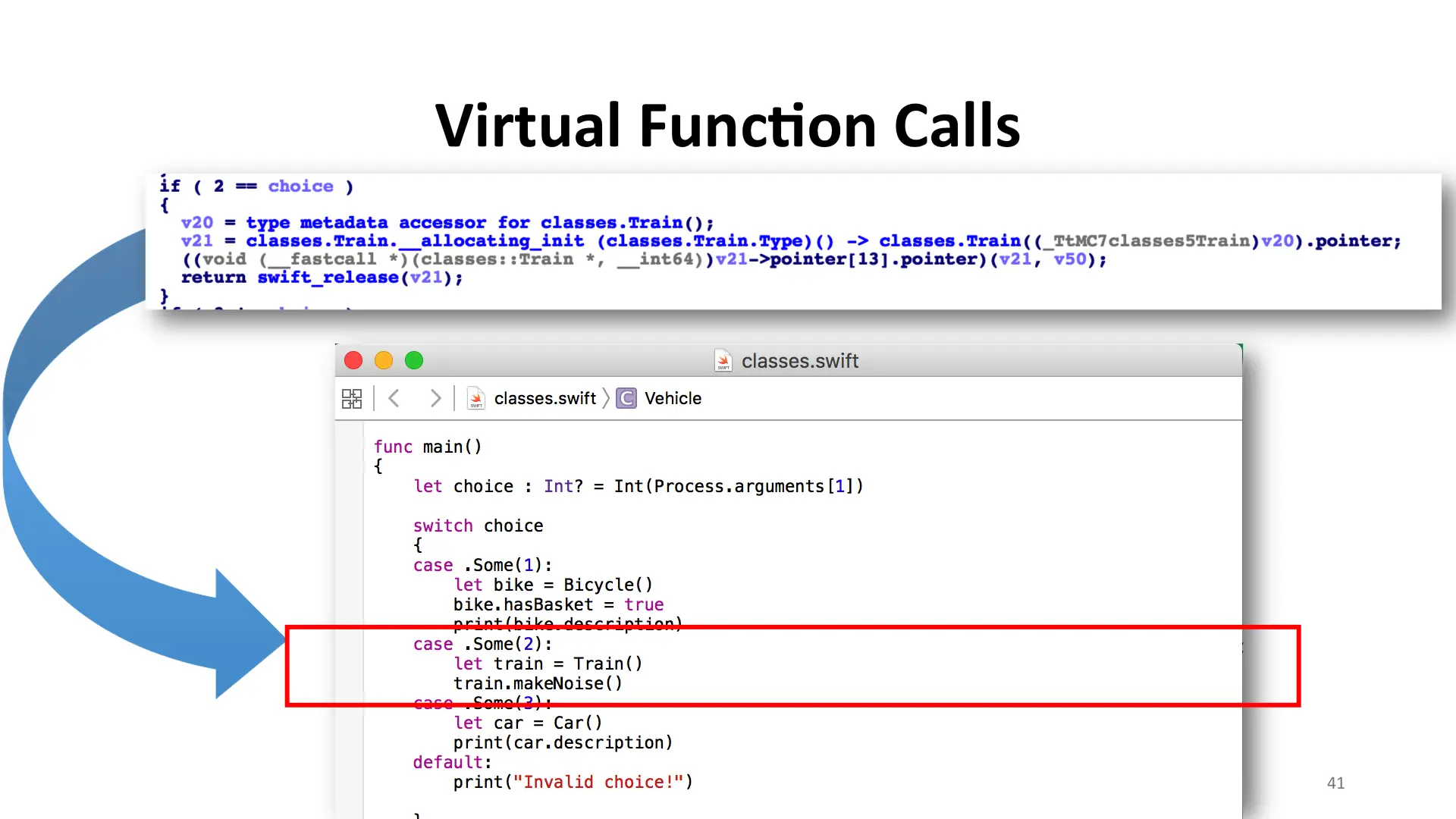
For virtual function calls, they're implemented basically identically to C++. Your instantiated class has a pointer to a table. In that table are a bunch of function pointers. You index into that and call the methods. The HexRays code above corresponds directly with the original source code.

Object ownership rules are pretty well defined in Swift, which is one reason why it's so safe. Everything in Swift is reference-counted with ARC. Well, that's not true, native types aren't reference counted, because that'd be slow and awful like java. Also, stack objects that don't escape aren't reference counted, but other than that, they're all automatically ref counted. This is possible because almost everything is derived from the HeapObject type, which includes a ref count, a data pointer, a type field, and some inline storage for smaller objects.
All this works because, as I pointed out early, functions advertise their ownership rules in their type signatures. Arguments can be: dead, guaranteed, exploded, guaranteed and exploded.

Swift generally follows a "whatever works best" calling convention, which is the most frustrating part of reversing it. HexRays doesn't understand it yet, so variables appear out of nowhere and are read from, but on closure introspection are actually return values from a preceding call. It makes sense, if your normal stdcall registers are alive but with values not involved in the call, but you have other registers that are dead, why not use the dead registers? or why not reorder the alive registers based on the call. Some compilers will do this when using LTO, as long as your function visibility is set properly. I'm sure many of you have encountered it there.
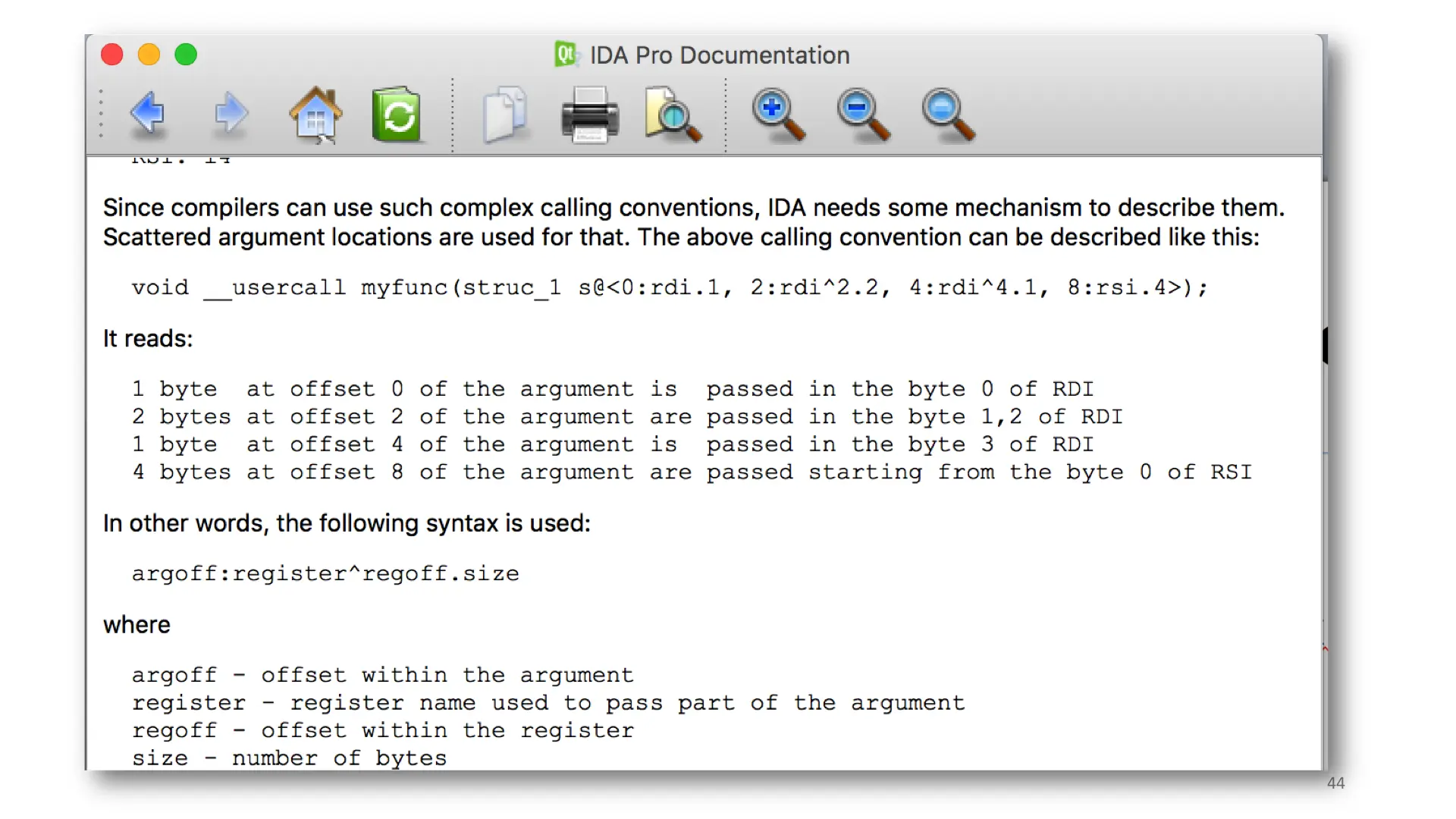
When searching for a solution to my problem, I discovered IDA's "Scattered Argument Syntax". Using this syntax, I was able to represent much of Swift's calls.

Either of these two types works properly in IDA and HexRays. Aren't they ugly? Also, this doesn’t scale to 4 register arguments yet.

Let's revisit our initial questions for the ABI. We now know that Swift bridges into ObjC seamlessly, virtual calls are nearly identical to C++, and __swiftcall is basically YOLO. I didn't mention it, but Swift classes are laid out in memory identically to ObjC classes -- in fact, the Swift implementation imposes additional restrictions on ObjC and ends up being the best documentation for the ObjC ABI.

Let's get to the tools.

To facilitate swift reversing, I have been working on a plugin you drop into your IDA plugins folder. I call it swift.py. I begrudgingly wrote it in python because it's too damn hard to write and support IDA plugins on OS X, but I generally stick to the C++ API.
Swift.py registers a callback to dynamically re-write all Swift mangled names into their demangled representation. It also annotates the IDA disassembly with the demangled names. It also does a small bit of class body recovery with member types.
I have a demo prepared for you all.

That's my talk. I'm Ryan Stortz, I'm on Twitter at @withzombies. Thank you. Questions?
This talk was originally presented in 2016 at Infiltrate in Miami Beach, FL, and ShakaCon in Honolulu, HI.